Good Morning Web World!
I found myself with a little bit of time this morning and I thought I’d share a bit of my latest tinkering.
Those of you that have followed this blog for a while may remember my first post where I talked about pointing a CUBE through an ASA out to my ITSP, Flowroute. That post is located here for your reading pleasure.
While the software/hardware has changed with my setup the idea is basically the same. I still have a CUCM system (now 11.x) running with a phone (I’ve felt like being different lately so currently I’m using a retro 7985G as my endpoint (G in this case does not mean Gigabit)). I also have a firewall, a Cisco 5506-X (it was time for an upgrade from the 5505) and I do still have a CUBE. My previous CUBE was a 3825 and it worked wonderfully but the 3825 has long since outlived its relevance in today’s enterprise environments. In my stack of possibilities I also have a 2921 and while it is still a very powerful and valid router, it just seems too easy.
Simple and straight forward is great but only until you’ve done simple and straight forward, then it becomes time to mix it up.
To that end, my replacement CUBE is virtual. Yes, I said virtual. If you follow Cisco and their products, you may already know about the Cloud Services Router, the CSR1000V. The CSR1000V is a virtual router that runs on a VMWare ESXi host. It runs IOS XE though there is some Linux/Unix on the backend that makes it tick.

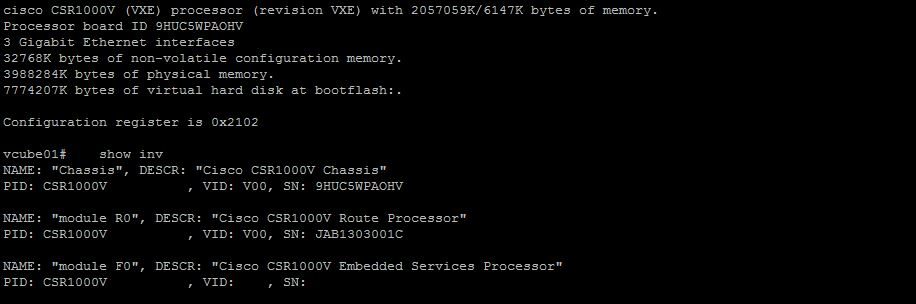
When I first heard that it was possible to turn a CSR1000V into a CUBE, I was skeptical. As I have worked through the configurations and witnessed it work, I must say I am impressed. The configuration is the same as with any other IOS XE router with exception of the interface naming conventions. There are three (3) Gigabit Ethernet interfaces and they are named Gigabit Ethernet 1, Gigabit Ethernet 2 and Gigabit Ethernet 3. The configuration in ESXi is shown below.

In my case, I created three (3) separate interfaces on my vSwitch and pointed them at three (3) separate VLANs in my infrastructure. You could bond/Port Channel these interfaces if you wanted too but you will still be limited by the throughput of your host’s uplink(s).
A few important things to note…
- When you deploy the OVA file in ESXi you are given a choice of multiple router “sizes” i.e. memory and processor. I am using the smallest size which is one vCPU and 4GB of vRAM. Some of the larger installations require an additional license.
- Keep in mind that I am testing this configuration in a controlled lab environment. I am not sure of scalability and if you read Cisco’s CUBE configuration guide, located here, you’ll see that the virtual CUBE does have several restrictions that may make it impractical for some organizations.
- The CSR1000V is a fully license-dependent platform. Once the demo runs out the router runs, but only with throttled performance. If you intend to deploy this solution, you will have to purchase licensing.
- In my previous post, my 3825 CUBE was running 12.4 IOS which did not include Toll Fraud Prevention, starting in 15.x and moving through IOS XE you need to be mindful of TFP and what it means when you are trying to make/receive calls on a Cisco H.323 or SIP Gateway.
Let’s talk for a moment on Toll Fraud Prevention. As stated above, all modern IOS and IOS XE versions include Toll Fraud Prevention mechanisms and if you use a router, physical or virtual, for voice you need to be aware of them.
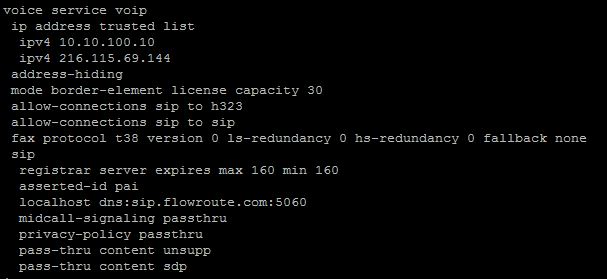
If you look at the configuration snippet above, you’ll see that in the voice service configuration there is a trusted IP Address list. That list contains the IPs of my ITSP and my CUCM. If I remove those IPs from the list, calls fail. If you are linking your CUBE or gateway to multiple CUCMs or other systems you’ll want to have those IPs in that list as well. What this list does is let the good/known IPs in to complete transactions/calls on the gateway/CUBE and keeps the unknown/bad IPs out to prevent them from placing calls on the system. IP addresses that are part of dial peers will be added to the list automatically but will not show up in the configuration. If you’ve ever set up an IP PBX on internet, you know that Toll Fraud is a real and serious threat. If you don’t want or need this feature you can turn it off by entering “no ip address trusted authenticate” in your voice service configuration. This is not a recommended configuration but in your environment the TFP mechanisms may do more harm than good.
Thanks for reading, I hope this has been informative.
-Justin
